Product, Review and FAQ schema: the unsexy reason AI keeps recommending your competitor
Schema markup is the most boring thing on your website. It is also the reason the AI keeps recommending a competitor whose products are objectively worse than yours. Your products exist, your prices are competitive, your reviews are good - but the AI cannot read what is on your product page unless it is labelled in a format the AI trusts. Right now, it probably is not.
Your competitor's developer spent two days adding Product, Review and FAQ schema. That two days is now buying their products a place in AI shopping recommendations that yours are not getting. Every day you do not have it, you are being quietly demoted inside Google AI Mode, AI Overviews and Perplexity - not because your products are worse, but because the AI cannot confirm they exist. It is the unglamorous foundation of the whole AI search shift.
What schema markup actually is
Schema is a structured-data format that sits inside your product-page HTML and tells search engines and AIs exactly what is on the page. The modern way to do it is JSON-LD - a small block of machine-readable code that labels everything the AI needs to know.
Without schema, an AI sees a page of unstructured text and has to guess. Sometimes it guesses right; often it does not. With schema, the page is labelled - the difference between handing someone a pile of receipts and handing them an accountant's spreadsheet. Same information, but only one is immediately usable.
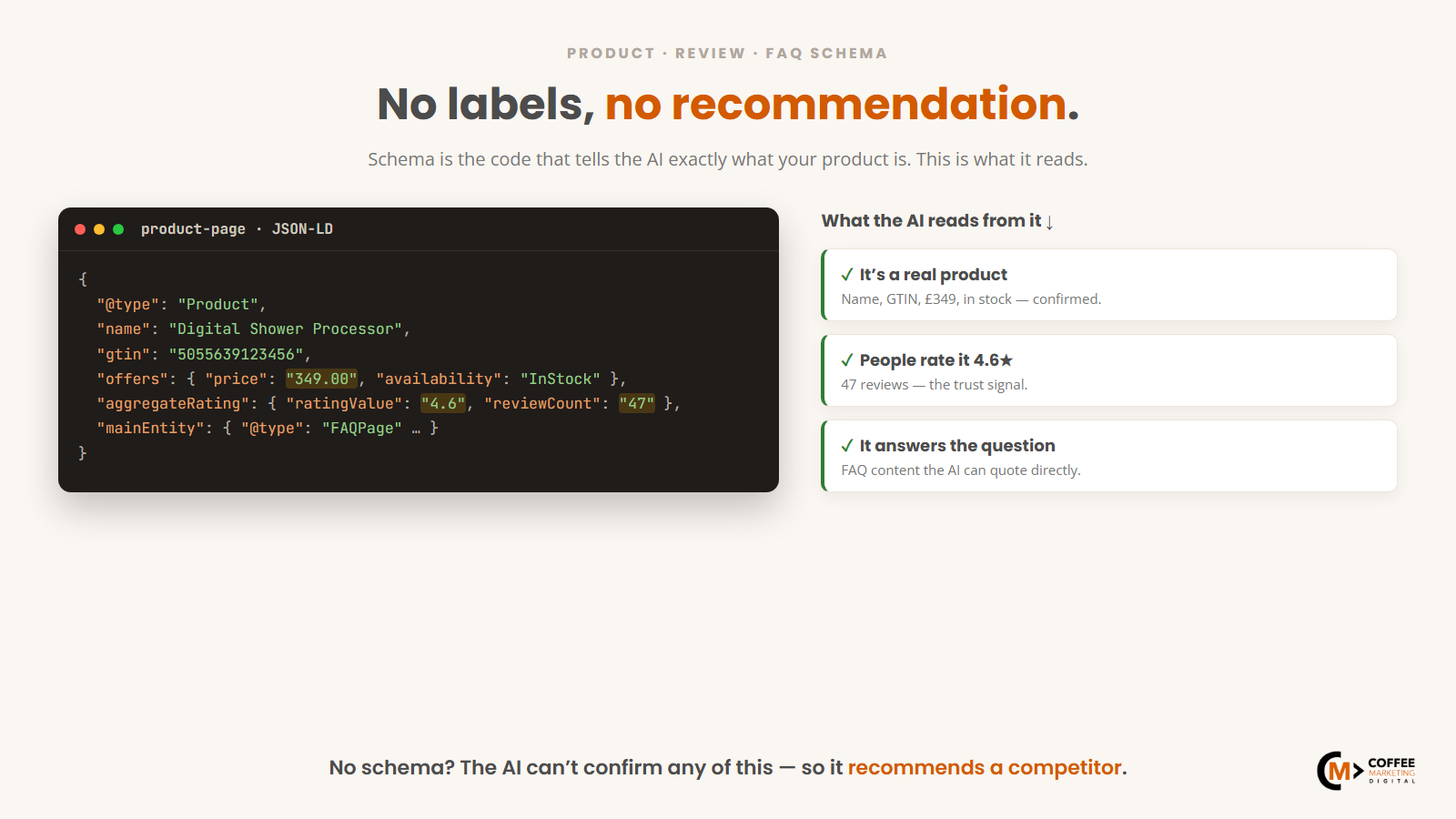
A well-labelled product page tells the AI: this is a product, the price is £349, the brand is Aqualisa, there are 47 reviews averaging 4.6 stars, and here are the customer questions and answers. The AI does not infer any of it - it reads the label. In code:
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Aqualisa Quartz Digital Shower Processor",
"brand": { "@type": "Brand", "name": "Aqualisa" },
"gtin": "5055639123456",
"offers": {
"@type": "Offer",
"priceCurrency": "GBP",
"price": "349.00",
"availability": "https://schema.org/InStock"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.6",
"reviewCount": "47",
"bestRating": "5"
}
}
Three types matter most for retailers. Miss any one and you have a gap the AI fills with your competitor's data instead.
Product schema - the foundation
The non-negotiable starting point. Without it, the AI has no reliable way to identify your product, compare its price, or confirm it is in stock. A complete block needs the name, brand, GTIN/MPN/SKU, price with currency (GBP, not a bare number), availability, at least one image URL, a description and item condition.
If you sell variants (sizes, colours, finishes), use AggregateOffer to cover the price range, rather than a single Offer that may not reflect what the customer sees.
The GTIN matters more than most retailers realise. AI agents recommending products across multiple retailers need a unique identifier to match them. Without a GTIN, the AI cannot confirm your Aqualisa Quartz is the same product listed cheaper on a competitor's site - so it defaults to the retailer that has the identifier. Usually not you.
Common failures: schema prices that do not match the page (tax-inclusive vs ex-VAT, B2B vs consumer), availability that has not updated since the last stock import, and missing GTINs on own-label or bundled products. It is the same data-quality problem the Conversational Attributes work fixes on the feed side.
Review schema - the trust signal
This is how the AI reads your social proof. It does not read the text of every review - it reads the schema. If your reviews are not marked up, the AI treats you as a product with no reviews, however many you actually have.
You need an AggregateRating (ratingValue, reviewCount, bestRating - almost always 5), and ideally individual Review objects too. The most common gap is the Trustpilot or Reviews.io widget trap: the reviews display beautifully via a third-party widget, but it renders client-side and never exposes the ratings as JSON-LD in the page source. The AI crawls the HTML, sees no schema, and concludes you have no reviews. The fix is to add AggregateRating to your product-page JSON-LD explicitly, pulling from your reviews platform's API.
FAQ schema - the conversation hook
FAQPage schema is how your product pages get into AI-generated answers. When someone asks "what is the difference between a digital and an electric shower", the AI stitches an answer from pages it trusts - and FAQ schema on a product page that answers it is a direct path in.
It needs Question and acceptedAnswer pairs that reflect real questions on the page, one block per product page, and the content must actually appear on the page (Google penalises invisible schema). Put it on individual product pages, not your global /faq - the value is the match between a specific query and a specific product-page answer. The questions worth marking up are the ones you already answer in descriptions, support chats and reviews; you just need to formalise them.
Why most retailers get this wrong
- Schema that does not validate. JSON-LD broken server-side is invisible to the AI. Use Google's Rich Results Test - if it does not show there, it does not exist for the AI.
- Price mismatch. Schema price not matching the page (currency formatting, ex-VAT vs inc-VAT, B2B vs consumer). AIs penalise mismatch heavily - it signals unreliable data.
- No Review schema despite having reviews. Trustpilot and Reviews.io widgets do not auto-produce JSON-LD. "We have reviews, so the AI knows" is wrong - you need explicit AggregateRating in the page source.
- FAQ schema on the wrong pages. Only mark up FAQs where the questions and answers are actually on the page. Off-page content is a policy violation and risks a manual action.
- Product schema on category pages. Product schema belongs on product pages; category pages use ItemList or BreadcrumbList. Wrong placement confuses the AI and can produce incorrect rich results.
Why this matters now
Google AI Mode and Perplexity both pull product data from schema before reading prose - structured data is parsed first because it is reliable; unstructured text is a fallback. We saw it in a recent live AI Mode test (anonymised): retailers with well-optimised feeds and structured data were picked up, while retailers relying on paid-search presence had no visibility inside the AI surface. Paid search buys clicks on traditional results; schema buys presence in AI recommendations - different budgets, different mechanisms, and most retailers are only funding one. (More on that in why ranking #1 no longer wins the sale.)
The work is small - a competent developer can audit your schema, fix the gaps and add FAQ markup to your top pages in a few days. The cost of not doing it is being demoted in every AI query for your category: quietly, automatically, indefinitely.
Where this sits in the bigger picture
Schema and llms.txt are two of the cheapest AI-readiness wins available to any retailer, at any stage. As we put it internally: "the audit checklist varies by stage, but every stage needs schema markup - it's the cheapest AI-readiness move you can make." Stage 1 needs basic Product schema with accurate pricing and availability; Stage 3 should have FAQ schema built from real customer questions; Stage 4 builds a full schema graph (Organisation, LocalBusiness, BreadcrumbList) for a complete, cross-linked picture. (See the maturity-model framing on the hub.)
Most retailers we audit are at Stage 1 or 2 on schema, however sophisticated their paid media is - because it does not show up in GA4 or a ROAS report. That is exactly why it gets skipped, and exactly why it matters.
From the team
"Schema is the least glamorous thing we do and the one that moves the needle most. It never shows up in a ROAS report, so it's the first thing retailers skip - which is exactly why the ones who bother are quietly pulling ahead in AI results."
— Alistair Williams, Coffee Marketing
Where to start
The fastest way to know where you stand is to see how your products show up in AI Mode, AI Overviews and Perplexity right now - including whether your schema is even being read. That is what our AI Visibility Report checks; if the gaps are structural, the technical fix (schema audit, JSON-LD, validation and a deployment plan your developer can run) follows from there.


